What is Chaos Engineering?
One of the reasons why I love my work as a Developer Advocate is that I continuously learn about new things and share them with the community. Last month, I shared that I am learning about Chaos Engineering!
So, now the challenge is if I can explain chaos engineering to you, then I’ve understood the concept well. 😄
In this post, I’ll explain basic concepts about chaos engineering as part of what I’ve learned and hopefully expand this in the future.
Trains and chaos engineering analogy
Let’s start with a toy analogy. I asked ChatGPT to explain chaos engineering to me like I’m a 5-year-old, and this is one of its responses, which I’ve tweaked a bit.
Imagine you have your favourite toy train set with different tracks and train cars. You want to be sure that everything works perfectly and that there are no problems when you play with it in different scenarios.
Let’s see it in practice:
- First, imagine how your toy train set should normally work. Think about how fast the trains should go, how many train cars they can pull, and how the tracks should be set up.
- Then, we come up with different things that could cause problems. This is where we experiment! For example, we might try making the trains go really fast or putting too many cars on the tracks, or even removing one of the tracks. What would happen to your train set under these different circumstances?
- Instead of doing all the experiments all at once. We pick a small experiment to start with, like making the trains go really fast. The main thing here as well is that we need to run the experiment on the actual train set, not a pretend one.
- When experimenting, we need to be sure that it doesn’t cause too much impact (blast radius, but more on this later!) to the other kids who are playing nearby.
- If your train set is still working after doing the experiment, you have more confidence that the train set is robust! You can then pick another experiment to try.
- If your train set doesn’t work after the experiment, you can ask your parents how to make it sturdier or ask them to get you a new train set (just kidding).
I hope that analogy was clear enough, but back to the real definition of chaos engineering!
Chaos engineering is the practice of deliberately introducing failures to your system to understand how your system responds to different failures that can manifest to your users.
For example, you may want to take down a random API or data service and see the side effect on your users’ applications. If the side effects are impactful and if you have Service Level Agreements (SLA) in place, then this can have a detrimental impact on your organisation.
Process of chaos engineering
Chaos engineering involves executing controlled experiments. An experiment looks like your typical science experiment and is typically done by:
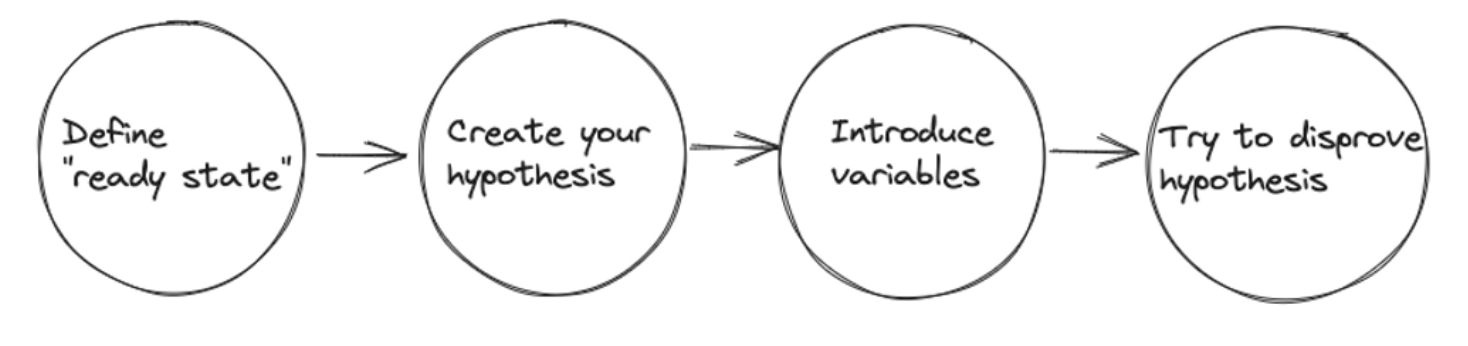
Define a ready state/steady state
This state describes what the expected output looks like for your system. A recommended practice is to define the state based on measurable metrics such as the expected response time, error rate, or resource utilisation rather than the overall system behaviour.
Create a hypothesis
Create a hypothesis that the steady state will continue for both the controlled and experimental groups. A sample hypothesis could be “When a server is terminated, the application should failover gracefully, and another node should handle the workload with no downtime or with little downtime of 10 minutes”.
Introduce variables
Introduce the necessary variables to support the hypothesis. In our sample hypothesis, this could be terminating one server. A recommended practice when introducing variables is to introduce variables one at a time.
Try to disprove your hypothesis
When running chaos experiments, our goal should be to disprove the hypothesis rather than to validate it. Look for any differences in the steady state between the controlled group and the experimental group. This is different from when we do testing in general. In testing, we validate the hypothesis or the expected result, but it’s the opposite in chaos engineering.
If the system doesn’t return to its steady state after running the experiment, this is an opportunity to improve your system’s robustness. On the other hand, if the steady state persists, then this means that your system is robust or the experiment was not chaotic enough.
You then continue introducing different variables and try to disprove the hypothesis as much as possible.
Principles of chaos engineering
In chaos engineering, there are also principles that serve as the foundation for executing these chaos experiments.
Focus on measurable output
When creating a hypothesis, this should be built around the steady state and focus on the measurable output of a system instead of its internal attributes. Create a hypothesis on how those outputs will change when an incident is introduced. A chaos experiment should verify that the system does work rather than trying to validate how it works.
Reflect real-world events
Your experiments should simulate real-world events such as servers crashing, mismanaging configuration settings, or a sudden spike in traffic. Any real-world events you think can potentially happen are great candidates for chaos experiments.
Run experiments in production
Since systems behave differently when exposed to different traffic and environment settings, running the experiments in production is preferable. However, tools such as xk6-disruptor, aim to challenge this principle by shifting chaos testing to the left.
Automate experiments to run continuously
When starting with chaos engineering, you can start small by terminating specific processes and observing the impact on your application. However, automated chaos experiments are more desirable and feasible in the long run. You could monitor results effectively, run the tests reliably, and scale chaos experiments faster if they were automated.
Minimise the blast radius
A blast radius refers to what is impacted by the chaos experiments. When starting a chaos experiment, start small and contain the impact. When the blast radius is hard to control, it will be difficult to track where the failure originated. This will also impact many people, especially when executing experiments in production environments.
Resources
- Principles of chaos engineering
- Chaos Engineering - notes by Nicole van der Hoeven
- What is Chaos Engineering? - video by Viktor Farcic (DevOps Toolkit)